



Milvus×滴滴:超3000w SKU的商超检索系统是如何炼成的
显著提升
整体用户搜索的转化效率
增强
用户体验
优化
数据管理与存储
滴滴最近推出了一项名为“Grocery Business”的新业务,正式进军生鲜电商领域。这一服务已经在墨西哥、哥伦比亚、哥斯达黎加等国家的部分城市亮相。
随着人工智能的发展,向量检索的应用场景越来越广泛,比较常见的应用场景有:语义检索、多模态检索、知识问答、推荐系统等。为了给用户带来更棒的体验并保持市场竞争力,Grocery 采用了向量数据库技术,打造了一个先进的商超搜索系统,并通过不断的创新和优化,让用户的生鲜电商之旅更加顺畅和愉悦。本文主要介绍外卖商超搜索场景下的向量化实战。
一、业务背景
在商超Grocery 业务的发展中,由于店铺内菜品数量可能达到3w, 对于店内搜索快速找到自己的心仪的商品主要路径,商品店内搜索成为了提升用户体验的核心功能之一。
然而,当前的搜索系统存在较高的“无结果率”,主要由以下几个因素引起:
- 用户输入错误:用户在搜索商品时,会出现单词拼写错误、英文和西语言混用、个性化的输入法等。传统的基于关键词匹配的搜索系统难以纠正这些错误,导致无法返回相关商品。
- 品类丰富度不足:商超商品的多样性导致用户的搜索需求各异,尤其是一些小众商品,用户可能用不同的表达方式进行搜索,而系统无法识别这些差异,最终导致搜索无结果。
线上的一些badcase:拼写错误和输入法是非常规字符:
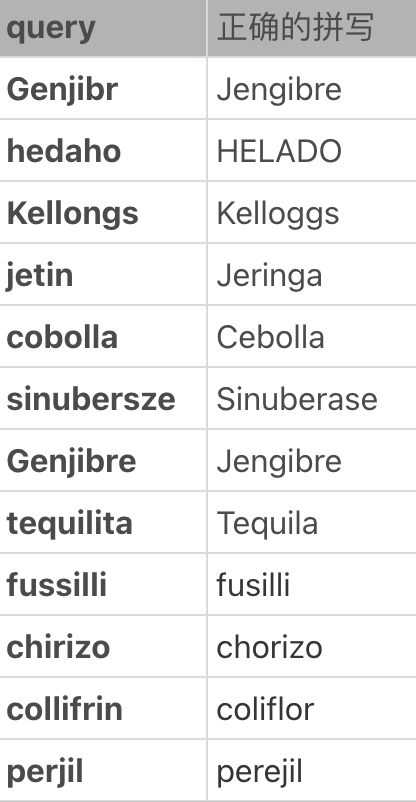 微信图片_20250225155230.png
微信图片_20250225155230.png
 微信图片_20250225155242.png
微信图片_20250225155242.png
面对这些问题,向量数据库结合语义搜索技术提供了一种强大的解决方案。通过语义匹配,我们可以大幅提升搜索的容错性和智能化,降低无结果率,增强用户的购物体验。
二、技术选型
- Milvus:专为大规模向量检索而设计的开源数据库,具备高性能和水平扩展性,能够处理数百万甚至数十亿的向量数据。
- Embedding 模型: 我们调研了智源的 BGE-M3 和Jina AI的 jina-embeddings-v3这两个模型, 这两个模型都可以对多语言进行一定的支持, 跟我们国际化的场景都很契合,像我们的主战场墨西哥这种地方,西语和英语是主流,但是会有很多中国人,韩国人在那边做生意
但是通过我们一些评测,在外卖商超商品的数据表现上
- jina 的效果更好,对多语言以及西语的支持更好,最多支持 89 种语言。
- BGE-M3性能更好,对中英文的支持更好,对西语支持的一般。
三、向量如何解决多语言问题
传统的关键词搜索依赖用户输入的精确匹配,而在不同语言间,描述同一商品的关键词往往千差万别。为了解决多语言搜索问题,我们采用了语义嵌入模型来将不同语言的文本转换为统一的语义空间中的向量表示。
- 嵌入模型的多语言能力:像 BGE-M3 和 jina-embeddings-v3 这样的嵌入模型,经过多语言语料库的训练,能够捕捉文本的语义含义,而不仅仅是词汇表面的相似性。无论用户输入的是中文、英文或其他语言,模型都会生成能够表示同一语义的向量。例如,用户在输入“苹果”或“apple”时,模型生成的向量在高维空间中非常接近,这样系统就能够返回同样的商品结果。
- 拼写错误的鲁棒性:向量化的表示也让系统具有一定的容错性。例如,当用户输入“appie”而不是“apple”时,嵌入模型依然能生成语义相近的向量,系统能够识别用户意图,提供正确的商品结果。
四、系统设计
商超商品库有超过 3000w 的菜品,而这些菜品很多都是重复的名字, 会导致 milvus 消耗大量的内存来存储这些向量数据。因此我们需要考虑如何进行数据的精简。
商品聚合:因为在一个模型中,相同的商品名的对应的向量是一样的。我们采取了商品名称聚合的策略,将相同菜品名称的商品合并,并为每个菜品名称维护一个对应的店铺列表。这样,商品库的向量存储量由 3000 万压缩至 20 万,极大地节省了内存,同时仍然保留了商品在不同店铺中的关联信息,同时因为数据量极大压缩,索引类型我们可以选择无压缩的IVF_FLAT,提高搜索准确性。
向量搜索与结果过滤:当用户发起搜索时,系统首先在聚合后的菜品库中进行向量相似性搜索。检索结果会根据用户所在的店铺 ID 进行过滤,以确保返回的商品只属于用户当前所在的商店。这一步既保证了搜索效率,又确保了结果的准确性。
(1)milvus表结构设计
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
(2)Embedding
由于jina-embedings-v3模型在 CPU机器上的表现不佳(5s/record), 因此我们选用 luban 平台提供的 GPU 机器来进行 embedding 的加速(50ms/record)
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
(3)调度
由于向量搜索主要用于补充召回,且对时效性的要求较低,同时实时更新商品表的成本较高,我们决定采用 T+1 的更新方式,每天对数据进行向量化并写入 Milvus。向量化过程依赖于 GPU 资源,因此我们通过模型平台进行调度,以确保资源的高效利用。
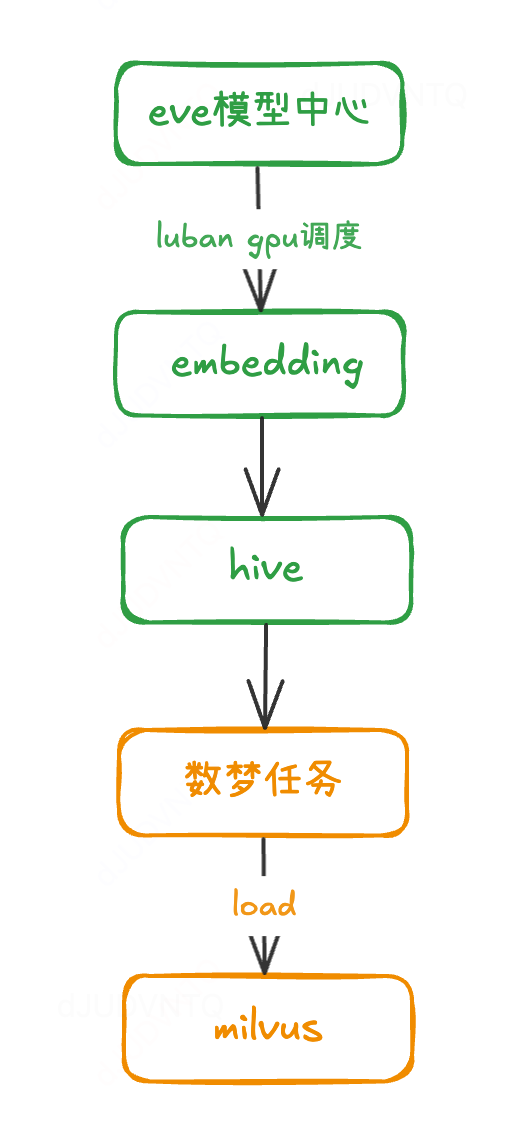 微信图片_20250225155246.png
微信图片_20250225155246.png
 微信图片_20250225155250.jpg
微信图片_20250225155250.jpg
(4)搜索流程
我们整个搜索分成两个部分,一个部分是之前 ES 的文本搜索链路,另外一个就是Milvus 的向量搜索链路,向量搜索结果目前作为ES少无结果的补充
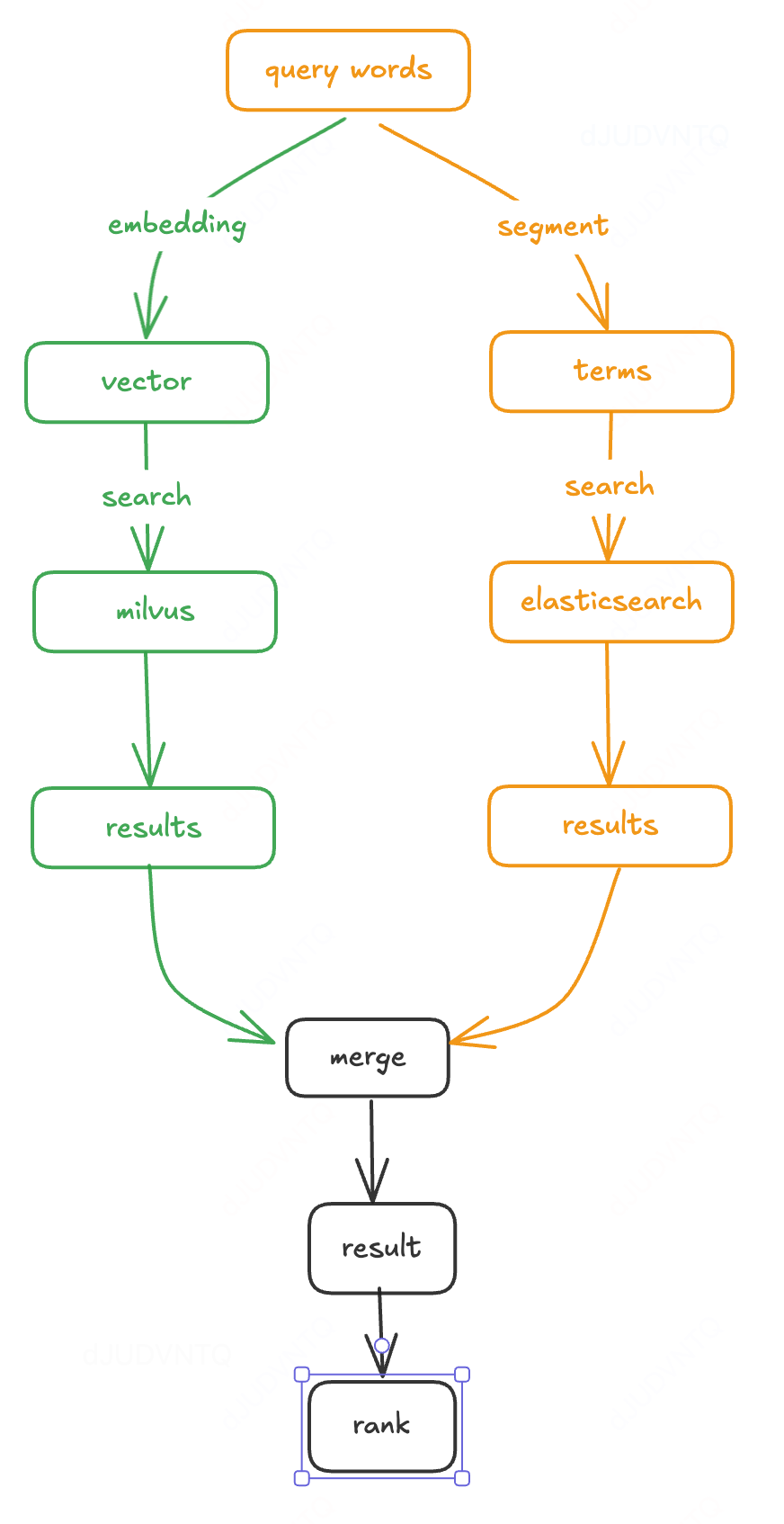 微信图片_20250225155254.png
微信图片_20250225155254.png
向量搜索过程
- 用户输入查询:用户在搜索框中输入商品名称或描述,可能包含拼写错误或使用不同语言。
- 语义向量化:系统调用 jina-embeddings-v3 模型将用户输入的文本转换为高维向量表示。
- 相似性搜索:通过 Milvus 进行向量检索,找到聚合菜品库中与用户输入最相似的菜品向量。
- 结果过滤:从相似菜品中筛选,确保返回结果为有效的库存。
- 结果聚合:与文本检索结果进行聚合,作为文本搜索的补充。
五、效果对比
(1)无结果query评测
选取线上无结果的query进行向量召回,其中19%的query召回了高相关性的结果,这类query也就是上文提到的,输入错误的场景。
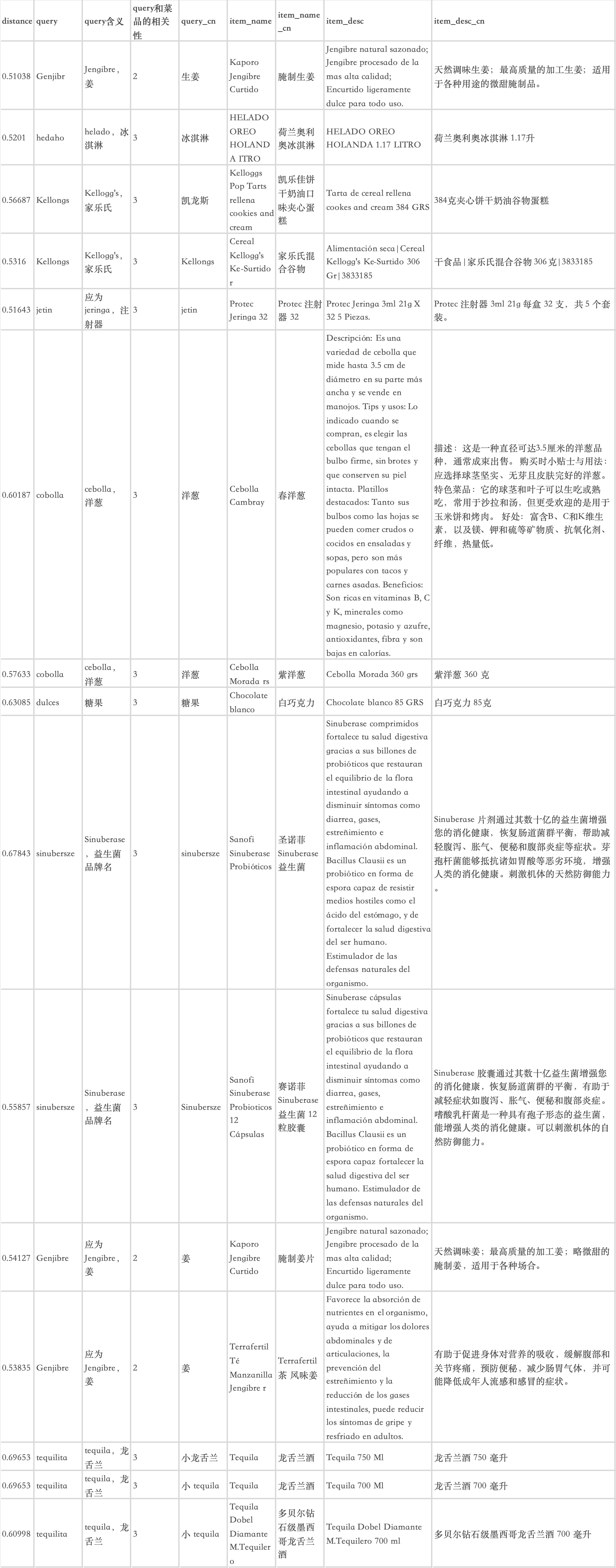 微信图片_20250225155257.png
微信图片_20250225155257.png
(2)多语言效果
搜索:液体妆前乳、liquid foundation(英语)、Base de maquillaje líquida (西语)
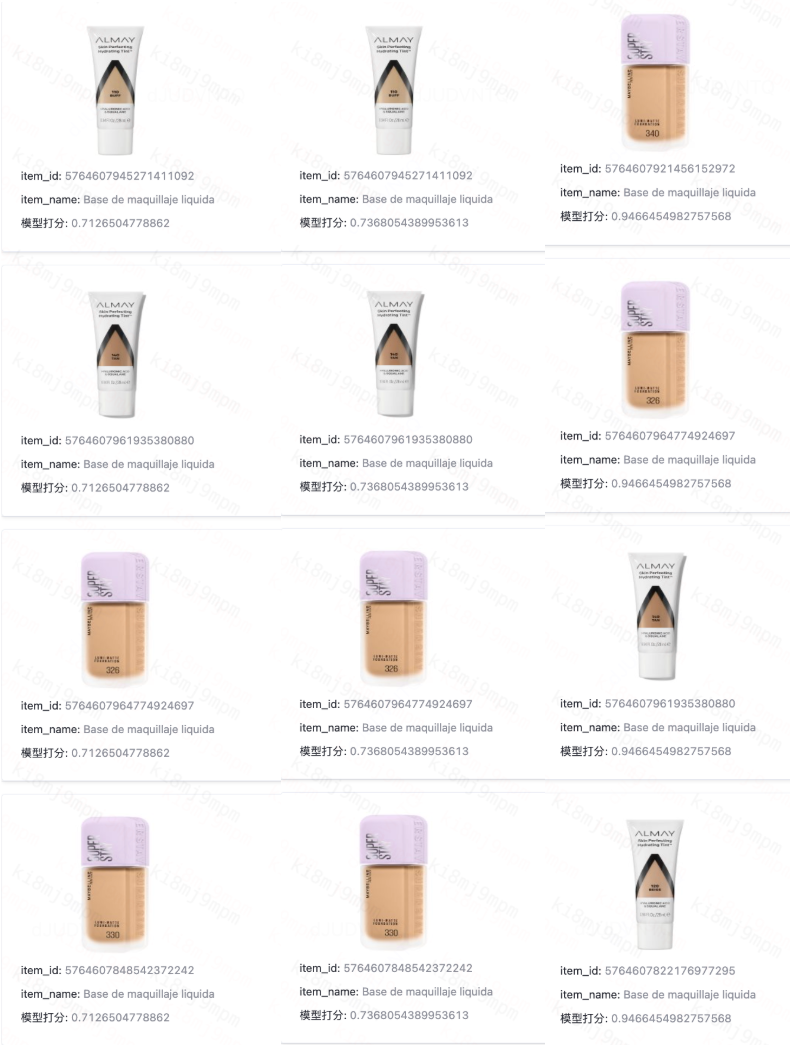 微信图片_20250225155301.png
微信图片_20250225155301.png
搜索:面包、bread、pan
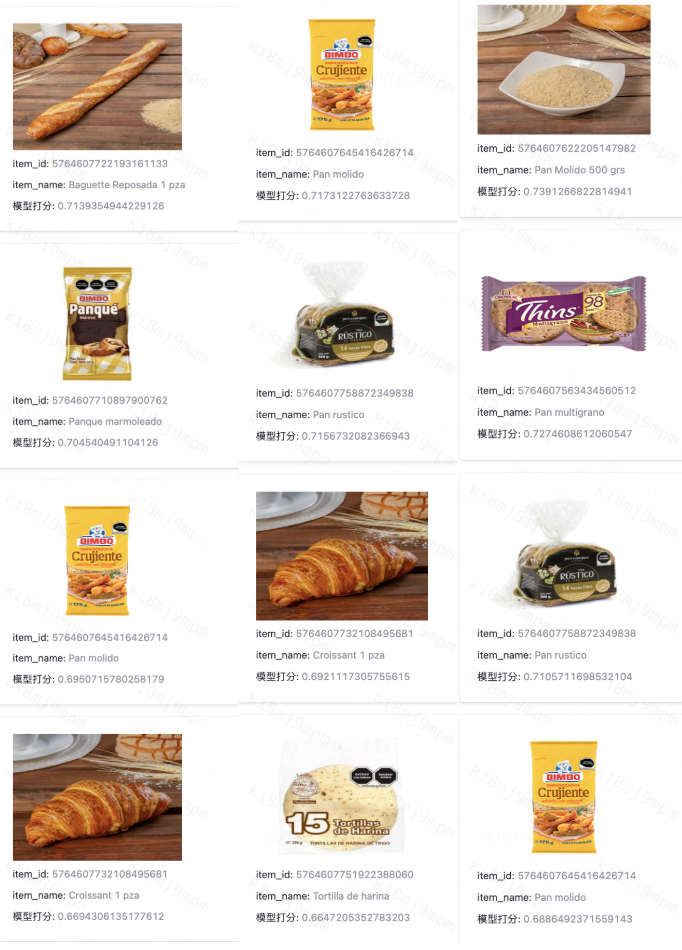 微信图片_20250225155305.png
微信图片_20250225155305.png
搜索:多级发动机油、Multigrade Motor Oil(英文)、Aceite para Motor Multigrado(西语)
 微信图片_20250225155309.png
微信图片_20250225155309.png
(3)与es文本检索效果对比(左-向量检索,右-文本检索)
搜索词:Redac PalancaPara WC Blanca 白色卫生间冲水杆
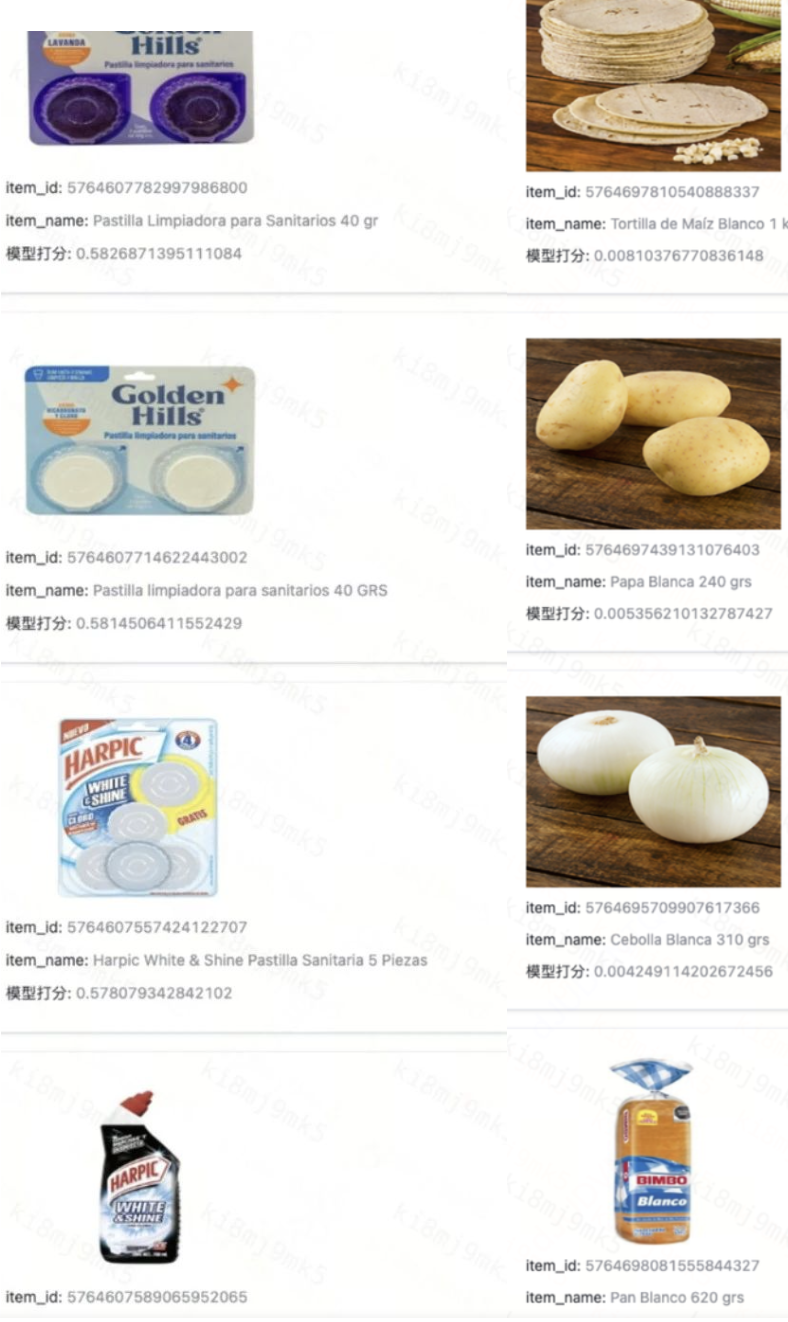 微信图片_20250225155312.png
微信图片_20250225155312.png
pañales extra jumbo 纸尿裤
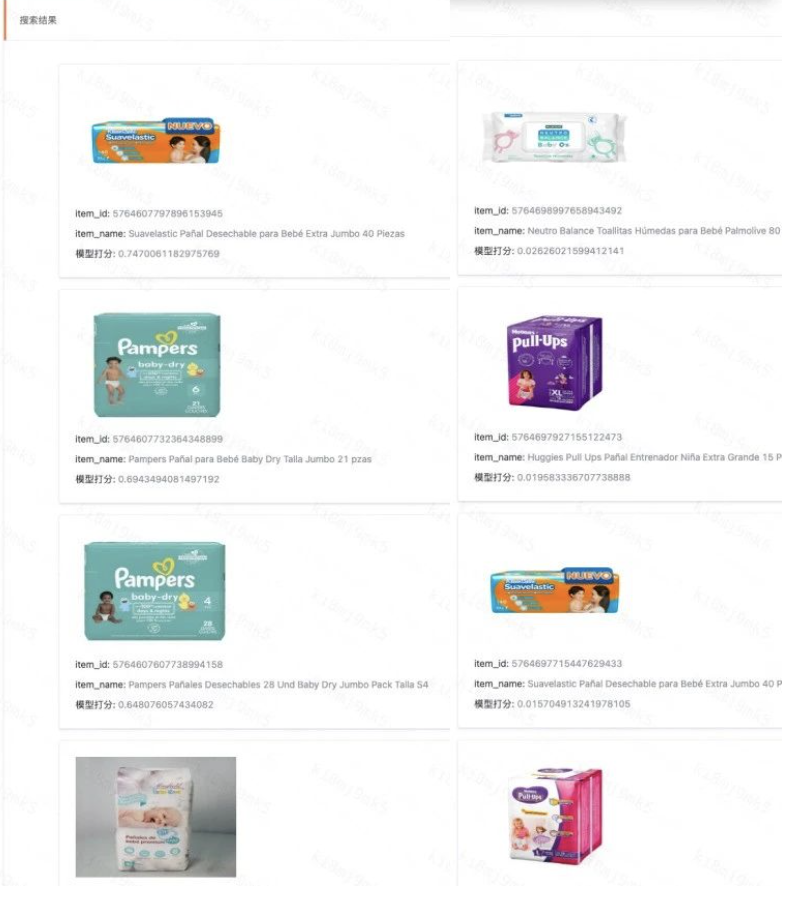 微信图片_20250225155316.png
微信图片_20250225155316.png
3.Pasteles 蛋糕
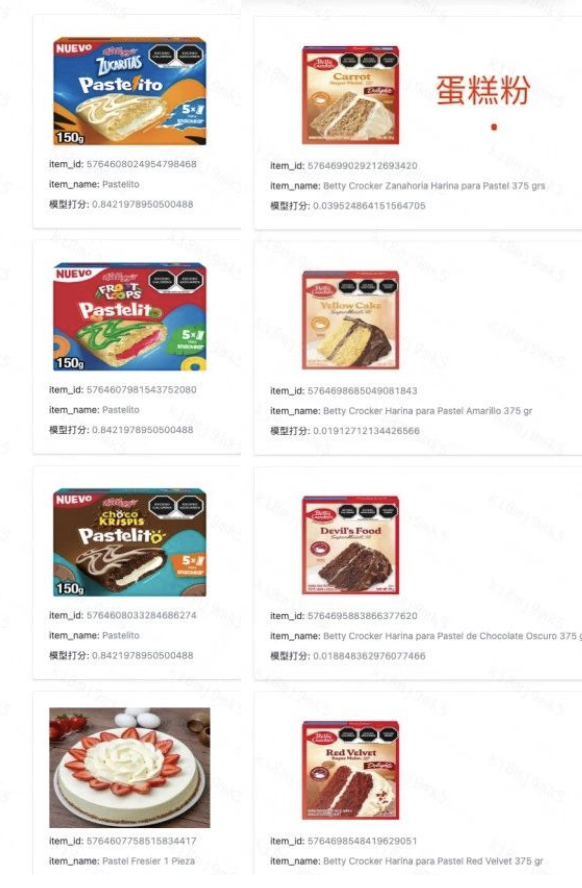 微信图片_20250225155320.png
微信图片_20250225155320.png
(4)不同模型效果对比
左侧是使用jina进行向量化的检索结果,右侧是使用bge-m3模型,jina的表现明显好于bge-m3,检索语言是西语。
medias negras 黑色袜子
 微信图片_20250225155323.png
微信图片_20250225155323.png
Tinte 染发剂
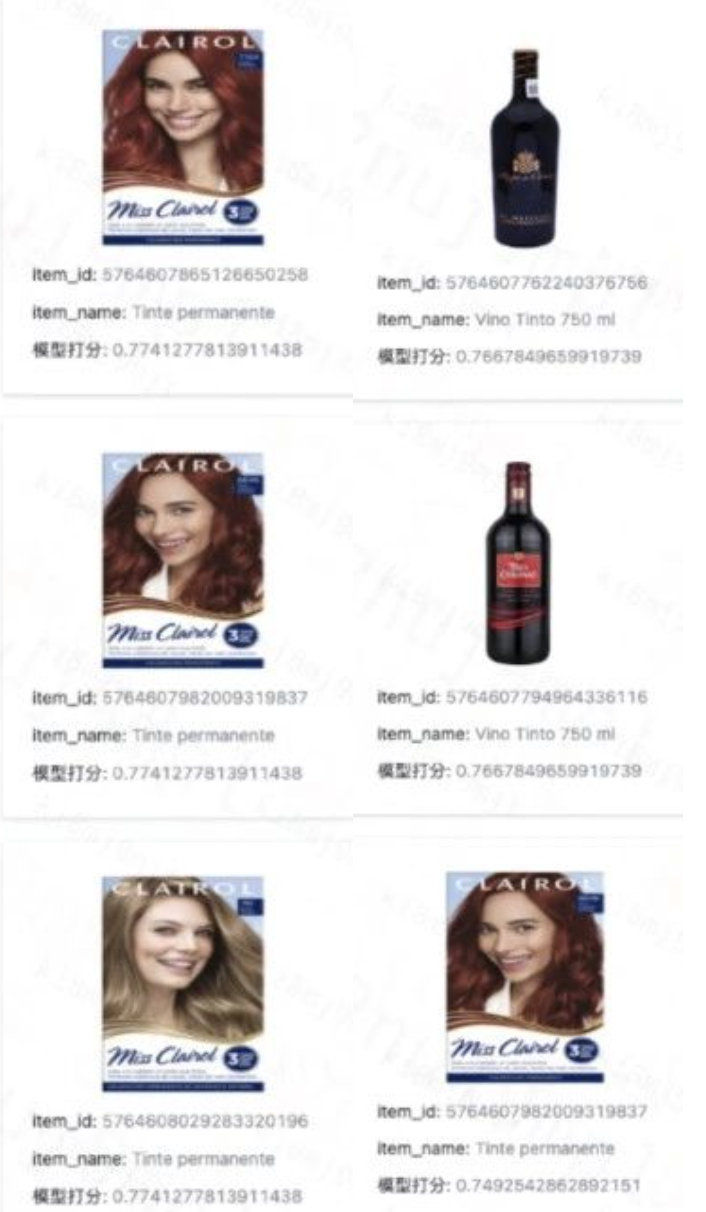 微信图片_20250225155327.png
微信图片_20250225155327.png
六、上线收益
Milvus上线以来,当用户搜索无结果或者结果不理想时,系统触发向量搜索作为补充召回,目前触发率在15%左右,而向量搜索结果曝光之后,用户添加购物车的占比是4%,这显著提升了整体用户搜索的转化效率。
如下两个指标分别为:向量搜索曝光率和用户加购率。
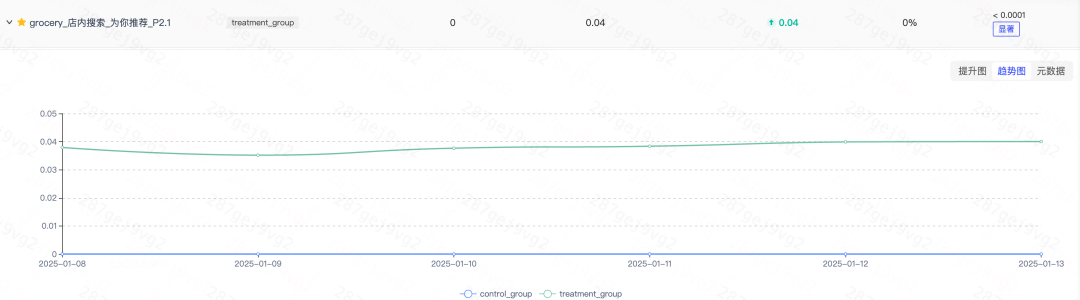 微信图片_20250225155334.png
微信图片_20250225155334.png
七、未来展望
为了进一步提升系统的表现,我们可以在以下几个方面进行扩展和优化:
- 动态数据更新:随着商品的新增或下架,设计动态更新机制,确保向量数据库中的商品数据及时同步。
- 个性化推荐:基于用户的历史搜索行为和购物偏好,结合向量搜索实现更为精准的个性化推荐。
- 混合搜索:结合其他维度信息(如价格、销量、评分等),对向量搜索结果进行加权处理,提升搜索的个性化和用户满意度。
参考资料
mteb 模型排行版:https://huggingface.co/spaces/mteb/leaderboard
baai/bge-me模型介绍:https://huggingface.co/BAAI/bge-m3
jina-embeding-v3模型介绍:https://huggingface.co/jinaai/jina-embeddings-v3
美团向量检索实践:https://tech.meituan.com/2024/04/11/gpu-vector-retrieval-system-practice.html
milvus实践:https://milvus.io/docs
elasticsearch混合搜索:https://www.elastic.co/guide/en/elasticsearch/reference/8.12/knn-search.html#_search_multiple_knn_fields
行业
互联网服务