



Hello Vector DB|认识一下,这才是真正的向量数据库

什么是向量数据库?
非结构化数据呈爆炸式增长。而我们可以通过机器学习模型,将非结构化数据转化为 embedding 向量,随后处理分析这些数据。在此过程中,向量数据库应运而生。向量数据库是一套全托管的非结构化数据处理解决方案,可用于存储、索引、检索 embedding 向量。
宏观解读向量数据库
ImageNet 可以说是最受欢迎的图像分类数据集。猜猜共有多少人参与了标记 ImageNet 数据集图片?
答案是:多达 25000 人。
那我们能否避免这种人工标记数据、打标签的方法,通过图片、视频、文本、音频等非结构化数据的本身内容来进行检索呢?快来试试向量数据库吧!如今,强大的机器学习模型配合 Milvus 等向量数据库的模式已经为电子商务、推荐系统、语义检索、计算机安全、制药等领域和应用场景带来变革。
让我们来转换一下视角。作为一个用户来说,如果没有方便的 API,再好的技术也没有用!此外,作为用户,我们还希望向量数据库能够具备更多重要的特性,包括:
可灵活扩展、支持调参:当向量数据库中存储的非结构化数据量增长至数亿或数十亿时,支持跨节点水平扩展这一特性显得至关重要。因为,肯定没有人愿意通过每 3 个月在服务器中手动插入一次 RAM 内存条这种方法来实现扩展!此外,由于数据插入速率、查询速度和基础硬件条件会根据应用场景而有所变化,所以向量数据库还需要支持灵活调参。
多租户、数据隔离:为每一个新用户的数据创建一个全新向量数据库,显然不合常理。因此向量数据库需要支持多租户。同时,通过支持数据隔离,只有 collection 所有者允许共享数据时,collection 数据才对其他用户可见。否则,在向量数据库中对任何一个 collection 进行数据插入、删除、查询等操作时,其他用户均不可见。
完整的 API:如果没有完整的 API 和 SDK,基本算不上是真正的数据库。Milvus 向量数据库就提供了 Python、Node、Go 和 Java 等语言的 SDK,方便用户轻松连接和管理 Milvus 向量数据库。
直观的用户界面或管理控制台:直观的用户界面可以大大降低学习成本。用户可以通过界面来体验向量数据库发布的新功能和工具。
向量数据库与 ANN 算法库的区别
我在这个行业中常听到一个错误观念——向量数据库只是在 ANN(approximate nearest neighbor,近似最近邻)算法上封装了一层。但这种说法大错特错!
1. 向量数据库可以处理大规模数据,而 ANN 算法库只能处理小型的数据集
从本质上,向量数据库是一套完整的非结构化数据解决方案。正如前文所言,向量数据库具备诸多功能——云原生、多租户、可扩展性等。但诸如 FAISS 等都是轻量级 ANN 算法库,而不是全托管的解决方案。这些算法库的主要用于构建向量索引(一种数据结构),从而加速多维向量的最近邻检索。这些算法库可以轻松应对小型数据集。但是,随着数据集和用户数量不断增长,这些算法库无法处理大规模数据。
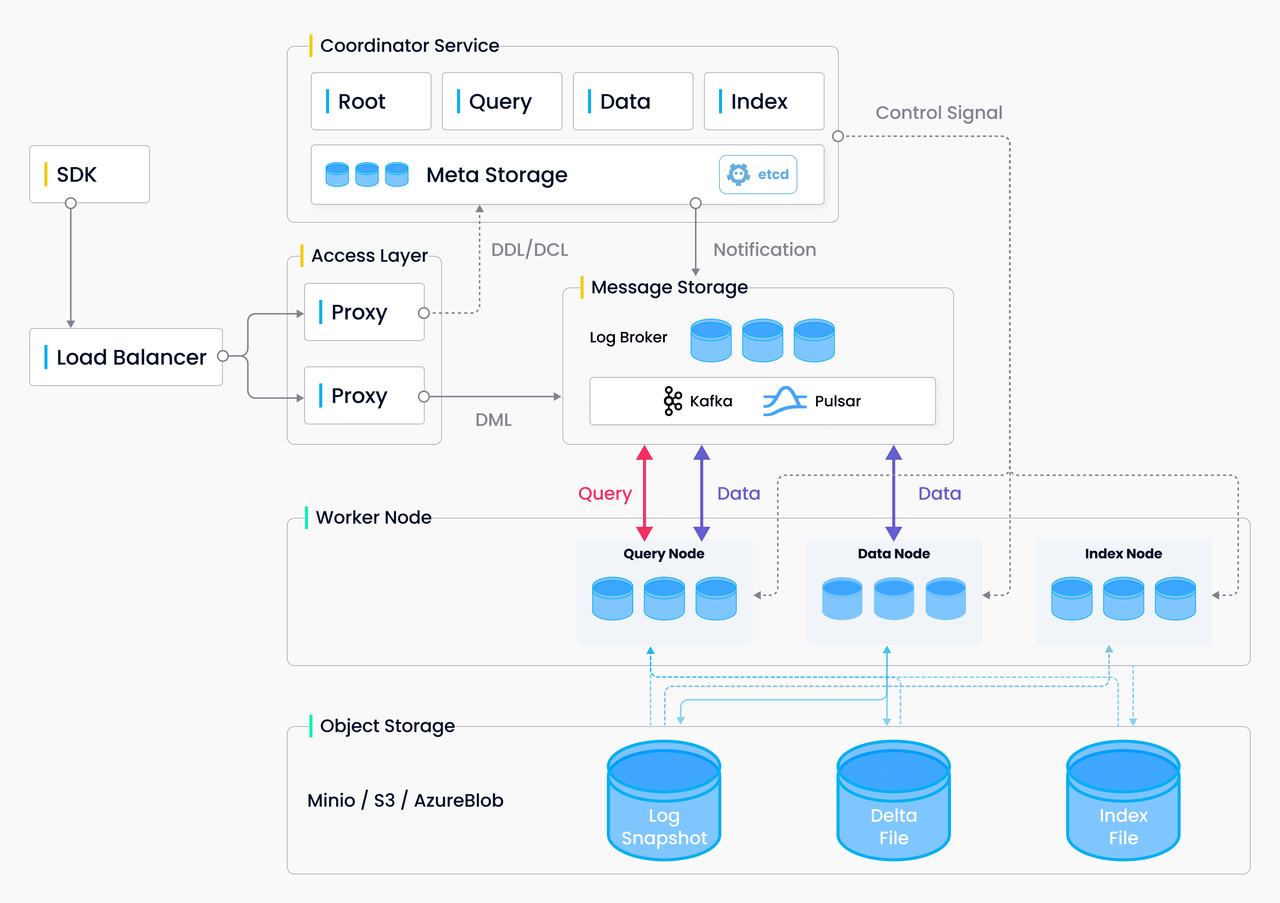 |Milvus 架构图
|Milvus 架构图
2. 向量数据库一套完整的解决方案,而 ANN 算法库只是其中一部分
向量数据库与 ANN 算法库另一大不同之处在于:向量数据库是一套完整的服务,而算法库是需要被集成到应用中去的。因此,从某种意义上而言,算法库是向量数据库的组件之一。这有点类似于 Elasticsearch 是一套基于 Apache Lucene 的搜索引擎解决方案。
为了具体说明这种区别, 我们来举一个例子。 在 Milvus 向量数据库中插入非结构化数据只需要三行代码即可。
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
但对于 FAISS 或 ScaNN 这样的算法库,没有这样可以简单插入数据的方法。即使自己通过代码实现插入数据,ANN 算法库仍然缺乏可扩展性和多租户等特性。
向量数据库与传统数据库向量检索插件的区别 越来越多的传统关系型数据库和检索系统(如 Clickhouse、Elasticsearch等)开始提供内置的向量检索插件。例如,Elasticsearch 8.0 支持通过 Restful API 来插入向量和开展 ANN 检索。但是,向量检索插件的问题显而易见——无法提供 embedding 向量管理和检索的全栈方法。这些插件仅可在现有的架构基础上用作优化方案,使用场景十分有限。在传统数据库基础上开发非结构化数据应用就如同在汽油车中安装锂电池和电动机一样不合常理。向量检索插件不支持灵活调参,也不提供易用的 API 或 SDK。但这两点是向量数据库的基本特性。为了展示向量数据库与向量检索插件的区别,文本将以 Elasticsearch ANN 搜索引擎为例。其他向量检索插件运行方式类似,因此不进一步展开。
Elasticsearch 的 dense_vector 字段支持向量数据类型,且可以通过 knnsearch endpoint 进行向量查询。
PUT index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 128,"index": true,"similarity": "l2_norm"}}}}
PUT index/_doc
{"image-vector": [0.12, 1.34, ...]}
GET index/_knn_search
{"knn": {"field": "image-vector","query_vector": [-0.5, 9.4, ...],"k": 10,"num_candidates": 100}}
Elasticsearch 的 ANN 插件仅支持 HNSW 一种索引和 L2(欧式距离)一种距离计算方法。但下面,让我们来使用向量数据库 Milvus(以 pymilvus 为例)。
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024},
"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
>>> search_param = {
'data': vector,
'anns_field': 'embedding',
'param': {'metric_type': 'L2', 'params': {'nprobe': 16}},
'limit': 10,
'expr': 'id_field > 0'
}
>>> results = collection.search(**search_param)
虽然 Elasticsearch 和 Milvus 都支持创建索引、插入 embedding 向量、执行 ANN 向量检索,但从以上示例中可以明显看出,Milvus 具备更直观的向量检索 API(可更好服务用户),支持更多样的向量索引类型和距离计算公式(方便用户灵活调参)。Milvus 还计划在未来支持更多的索引类型,并允许用户通过类似 SQL 语句进行查询,从而进一步提升向量数据库的可用性。
简而言之,诸如 Milvus 的向量数据库比向量检索插件更好用。因为 Milvus 是从零开始构建的向量数据库,相较而言,具备更丰富的功能和更适合非结构化数据的系统架构。
一些技术难点
在文章的前半部分,我们列举了一些向量数据库应该具备的特性,然后比较了向量数据库和 ANN 算法库、向量检索插件的不同之处。现在让我来看看构建向量数据库过程中会遇到的一些技术难点。在后续的文章中,我们会着重介绍 Milvus 向量数据库是如何克服这些难点,以及哪些技术决策成功帮助 Milvus 在性能方面超过其他开源向量数据库。
如同一架飞机一样,飞机中的每个零部件和系统相互连通,共同协作为我们提供愉悦的飞行之旅。同样,向量数据库包含一些列的组件,可粗略分为存储、索引和服务。虽然这三部分组件相辅相成,但是诸如 Snowflake 之类的公司已经向存储行业证明了 “Shared Nothing” 的数据库架构可能更优于传统云数据库的“共享存储(Shared Storage)”模式。那么,构建向量数据库的第一个难点来了。如何设计一个灵活、可扩展的数据模型。
有了数据模型之后,我们需要考虑第二个问题。将数据存储在向量数据库后,如何检索、查询这些数据并构建索引?机器学习模型和多层神经网络本质上重计算,因此 GPU、 NPU/TPU、FPGA 和其他通用计算机硬件繁荣发展。向量查询和索引构建同样重计算。使用上述硬件加速后,向量查询和索引构建的速度和效率都将大幅提升。多样的计算资源引入了第二个技术难点。如何设计一个支持异构计算的架构?
有了数据模型和架构之后,需要思考最后一个问题。应用系统如何从向量数据库中读取数据?这个问题的答案和 API、用户界面息息相关。想要以最低的成本取得最佳的性能,向量数据库作为一种全新的数据库类型催生了一种新的架构。但是我们需要记住,大部分的向量数据库用户还是习惯于传统数据库的 CRUD 操作(例如:SQL 中的 INSERT、SELECT、UPDATE、 DELETE )。因此,最后一个技术难点便在于如何开发一套与传统类似的 API 和 图形用户界面(GUI),但同时要确保与向量数据库的底层架构兼容。
总而言之,三个组件对应了三个技术难点。我们需要注意,世界上不存在什么可以拿来套用的通用型向量数据库架构。最棒的向量数据库应该解决上述几个难点,并同时提供前文中所列举的功能。
向量数据库的优势
向量数据库的主要应用领域为相似性检索、机器学习、人工智能等。与传统数据库比较,向量数据库具备以下几点优势:
高维向量检索:向量数据库可以高效进行高维向量相似性检索,非常适用于机器学习和人工智能应用中,如:图片识别、自然语言处理、推荐系统等。
可扩展性:向量数据库支持水平扩展,因此可以存储和处理海量向量数据。在实时检索和召回海量数据的应用场景中,向量数据库的可扩展性显得至关重要。
灵活性:向量数据库可以处理多样的向量数据类型,包括稀疏向量和稠密向量。此外,向量数据库还可以处理其他的数据类型,包括:数字、文本、二进制数据(Binary)。
性能:相较于传统数据,使用向量数据库进行相似性检索更高效。
支持选择不同索引结构:向量数据库支持用户根据不同的应用场景和数据类型构建不同的索引结构。
总结一下,向量数据库在相似性检索和机器学习场景中具有显著优势,能够快速、高效检索和召回高维向量数据。
如何寻找最合适的向量数据库
ANN-基准是一种用于评估各种向量数据库和近似最近邻(ANN)算法性能的工具。
数据集和参数规格:ANN 基准提供大小、类型、维度不同数据集。每套数据集匹配一套参数,如:检索的最近邻数量、使用的距离计算公式等。
计算召回率(search recall):ANN 基准计算召回率,即返回的 k 个近邻中包含真正最近邻的比例。召回率是用于评估系统向量检索准确性的重要指标。
计算 RPS:ANN 基准还可以计算 RPS(或者也叫 QPS,query per second),即向量数据库和 ANN 算法处理 query(查询请求)的速度。RPS 是用于评估系统速度和可扩展性的重要指标。
我们可以使用 ANN 基准,在同一条件下比较不同向量数据库和 ANN 算法的性能,从而更快速找到最合适的选择。
总结
本文全面介绍了向量数据库,分析了成熟向量数据库提供的特性,探讨了向量数据库与 ANN 算法库、传统数据库向量检索插件的异同。最后本文还阐述了构建向量数据库过程中的技术难点。
希望通过阅读本文后,大家能够大致了解什么是向量数据库。在后续的文章中,我们将更近一步介绍最受欢迎的向量数据库 Milvus 以及向量数据库的普遍应用场景。

Frank Liu


技术干货
打磨 8 个月、功能全面升级,Milvus 2.3.0 文字发布会现在开始!
七大变化详解 Milvus 2.3.0
2023-9-1
技术干货
Zilliz Cloud 明星级功能详解|解锁多组织与角色管理功能,让你的权限管理更简单!
Zilliz Cloud 云服务是一套高效、高度可扩展的向量检索解决方案。近期,我们发布了 Zilliz Cloud 新版本,在 Zilliz Cloud 向量数据库中增添了许多新功能。其中,用户呼声最高的新功能便是组织与角色的功能,它可以极大简化团队及权限管理流程。
2023-6-28
技术干货
如何在 Jupyter Notebook 用一行代码启动 Milvus?
本文将基于 Milvus Lite,为大家介绍如何在 Jupyter Notebook 中使用向量数据库。
2023-6-12