



如何检测和纠正GenAI模型中的逻辑谬误
大型语言模型(LLMs)已经彻底改变了人工智能领域,特别是在会话式AI和文本生成等方面。LLMs在数十亿参数的大量数据上进行训练,以生成类似人类的文本。许多公司期待开发基于LLM的聊天机器人来处理客户查询、接收评论、解决投诉等。随着LLM的使用和采用不断增长,我们需要解决一个关键问题:LLM输出中的逻辑谬误。解决这一挑战,使AI系统更具责任感和可信度至关重要。
Jon Bennion是一位在应用机器学习、AI安全和评估方面拥有丰富经验的AI工程师,他最近在由Zilliz主办的非结构化数据聚会上讨论了一种有趣的处理逻辑谬误的方法。Jon是LangChain的杰出贡献者,实现了处理输出谬误的新方法。
**观看Jon演讲的回放**
在他的演讲中,Jon解释了模型推理中可能导致逻辑谬误的常见陷阱。他还讨论了识别和纠正这些谬误的策略,强调了使模型输出与逻辑上合理和类似人类的推理一致的重要性。
**什么是逻辑谬误?**
图1:什么是逻辑谬误?
图片来源:https://arxiv.org/html/2404.04293v1/x1.png
在查询LLMs时,在某些情况下,输出可能因逻辑原因而有缺陷,或与问题无关。逻辑谬误包括人身攻击、循环推理、权威诉求等。它们通常基于小样本量进行广泛的概括,例如:“我的一个来自法国的朋友很粗鲁,所以所有法国人一定都很粗鲁。”
在一些情况下,它可能假设某件事是真实的或正确的,因为它很受欢迎。
示例:“每个人都在使用这个新应用程序,所以它一定是最好的。”有时,LLMs很难记住早期的对话细节,无法提供准确的响应。
**为什么会出现逻辑谬误?**
有许多原因可能导致逻辑谬误的出现,以下是最主要的原因。众所周知,LLMs并没有被完美地训练来像我们的大脑那样处理所有情况。
**不完美的训练数据**
我们提供的用于训练的数据来自互联网上的各个来源,并不完美。它包含了许多人的偏见、不一致之处,甚至是边缘案例中的虚假信息。在训练期间,LLM暴露于有缺陷和不一致的推理中,并且也学会了这些。如果训练数据中有有缺陷的论点,它将学会这些模式并在响应中模仿它们。
**小的上下文窗口**
在演讲中,Jon提到,“小的上下文窗口可能会导致响应问题。许多团队努力优化上下文窗口以满足内存需求和性能。”
上下文窗口指的是LLM一次可以考虑到的信息量,它是固定的。当上下文窗口较小时,模型可能会遗漏重要细节,无法形成连贯的答案。这可能导致诸如草率概括或虚假二分法等谬误。
**概率性质**
LLM基于序列中哪个词更有可能来生成文本。它们无法像人类那样理解词的真实含义。我们训练模型在给定上下文的情况下实现局部连贯性。有时,这可能导致逻辑谬误,因为可能会遗漏更广泛的上下文。
**如何解决逻辑谬误?**
检测并防止LLM产生逻辑有缺陷的响应至关重要,以便用户可以信任它。Jon简要讨论了解决这个问题的常见做法,如人工反馈、强化学习、提示工程等。
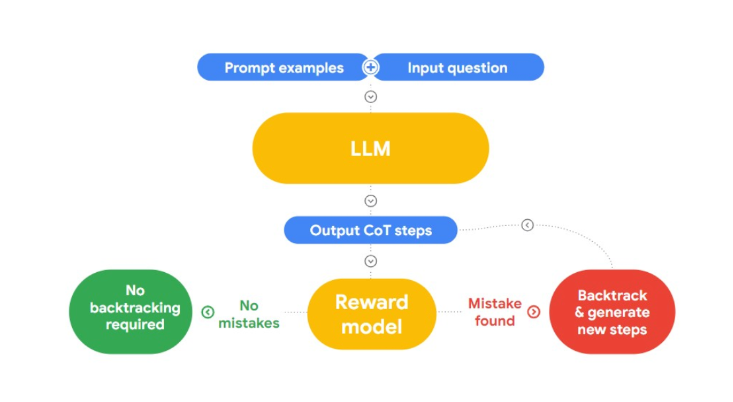
在这次演讲中,Jon提出了一种检测和纠正逻辑谬误的有趣方法,“RLAIF”。这里的想法是使用AI自我修复。
**图2:RLAIF如何工作?**
他引用了研究论文“使用语言模型进行案例推理以对逻辑策略进行分类”,这对我们的问题很有用。论文介绍了案例推理(CBR),以对逻辑谬误进行分类。它分为三个阶段:
**检索:**我们为CBR提供了一个包含逻辑谬误和人为识别的文本数据集(案例库)。当提供新文本时,CBR将在案例库中搜索类似案例。
**适应:**检索到的案例随后被适应到新论点的特定上下文中,考虑到目标、解释和反驳等因素的影响。
**分类:**基于可用信息,CBR识别并分类任何逻辑谬误。
Jon采用了这种方法,进一步发展了它,并在LangChain中实现了一个谬误检测设施。
**使用LangChain的谬误链防止逻辑谬误**
Jon通过提示模型提供包含逻辑谬误的输出来演示一个例子。下面的例子显示了一个输出,它受到了“权威诉求”的影响,并且在逻辑上有缺陷。
# 模型输出包含逻辑谬误的示例
misleading_prompt = PromptTemplate(
template="""You have to respond by using only logical fallacies inherent in your answer explanations.
Question: {question}
Bad answer:""",
input_variables=["question"],
)
llm = OpenAI(temperature=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="How do I know the earth is round?")
输出:
'The earth is round because my professor said it is, and everyone believes my professor'
这是一种逆向工程方法,我们定位模型学到的谬误,然后防止它使用它们。
Jon解释了我们如何可以使用LangChain的FallacyChain模块来进行更正。首先,我们使用误导性提示初始化LangChain以突出显示当前的谬误。
fallacies = FallacyChain.get_fallacies(["correction"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="How do I know the earth is round?")
接下来,我们初始化一个Fallacy Chain,提供误导链作为输入和LLM模型。它将检测存在的谬误类型并通过删除它来更新响应。
> 进入新的FallacyChain链...
初始响应:地球是圆的,因为我的教授这么说,每个人都相信我的教授。
应用更正...
谬误批评:模型的响应使用了权威诉求和民意诉求(每个人都相信教授)。需要谬误批评。
更新后的响应:你可以通过实证证据来找到地球是圆的证据,比如来自太空的照片,船只消失在地平线上的观察,看到月亮上的弯曲阴影,或者能够环球航行。
> 完成链。
'你可以通过实证证据来找到地球是圆的证据,比如来自太空的照片,船只消失在地平线上的观察,看到月亮上的弯曲阴影,或者能够环球航行。'
Jon深入研究了Fallacy Chain模块的工作原理,他将其整合到了LangChain中。Fallacy Chain的架构有两个主要组成部分:Critique Chain和Revision Chain。提示工程在两个链中都被利用来检测和修改响应中的谬误。快速了解它的工作原理:
当我们提供输入时,LLM处理它并生成初始响应。
下一步是谬误检测。Critique链根据识别出的模式识别和分类任何存在的谬误。Jon提到利用之前提到的研究论文中提取和使用的谬误列表。
修订链通过提示工程编码,重新生成避免检测到的谬误的修订响应。这可能涉及重新表述、添加上下文或改变论证结构。
**演示应用**
Jon还演示了一个从新闻文章中提取逻辑谬误的应用。在这个演示中,他展示了不同地区的最新文章可能具有政治、权威偏见。他还演示了一个使用Open AI构建的应用,用于提取给定主题的最新文章并识别它们的顶级谬误。使用这个应用程序,他搜索了与“中国”作为关键词相关的最新文章,输出结果如下所示。
新闻文章解释了Fallacy Chain如何识别并解释了“权威诉求”问题。Jon讨论了这些工具如何从逻辑谬误中清理我们的训练数据,为模型提供无缺陷的学习。FallacyChain可以显著提高LLM输出的可靠性,并增加用户信任。它还通过解释更改及其原因提供透明度,帮助用户理解如何实现逻辑连贯性。
有关这个演示的更多信息,请**观看Jon聚会演讲的回放**。
**结论**
LangChain中的FallacyChain是提高LLM生成文本逻辑完整性的强大方法。它可以增加用户之间的信任,并使LLMs的实施更容易符合合规性。虽然优势令人惊叹,但评估在大规模实施它的成本是必要的。这是一个令人兴奋的领域,新的实验正在进行,以使用机器学习方法进行谬误分类等来改进它。

Abdelrahman Elgendy
Freelancer Technical Writer


技术干货
如何在 Jupyter Notebook 用一行代码启动 Milvus?
本文将基于 Milvus Lite,为大家介绍如何在 Jupyter Notebook 中使用向量数据库。
2023-6-12
技术干货
向量数据库发展迎里程碑时刻!Zilliz Cloud 全新升级:超高性价比,向量数据库唾手可得
升级后的 Zilliz Cloud 不仅新增了诸如支持 JSON 数据类型、动态 Schema 、Partition key 等新特性,而且在价格上给出了史无前例的优惠,例如推出人人可免费使用的 Serverless cluster 版本、上线经济型 CU 等。这意味着,更多的开发者可以在不考虑预算限制的情况下畅用云原生向量数据库。
2023-6-15
技术干货
可处理十亿级向量数据!Zilliz Cloud GA 版本正式发布
本次 Zilliz Cloud 大版本更新提升了 Zilliz Cloud 向量数据库的可用性、安全性和性能,并推出了一系列新功能。这次升级后,Zilliz Cloud 能够更好地为用户提供面向各种应用场景的向量数据库服务,不断提升用户体验。
2023-4-7