




如何实现 Delivery Hero 的 AI 生成图像安全系统
作为一家跨国在线食品配送公司,**Delivery Hero** 将顾客与其所地区的餐厅联系起来。因此,公司理解双方的需求以维持他们对 **Delivery Hero** 服务的总体满意度至关重要。
在柏林 **Zilliz Unstructured Data Meetup** 的一次演讲中,**Delivery Hero** 的两位数据科学家 Iaroslav Amerkhanov 和 Nikolay Ulyanov 讨论了他们的研究项目,旨在简化餐厅供应商和顾客的需求。
**观看聚会演讲的回放**
基于内部统计数据,**Delivery Hero** 发现了一个有趣的事实:在应用程序中附有图像的产品比没有图像的产品更频繁地被订购。具体来说,86% 在应用程序上订购的产品附有图像。在进行 A/B 测试后,他们还发现仅通过为产品添加图像,转化率就增加了 6-8%。这一发现意味着产品图像是顾客在 **Delivery Hero** 应用程序上订购食品之前的关键因素之一。
然而,要求每个餐厅或供应商提供其产品的图像可能是麻烦的,因为并非每个供应商都能提供吸引人的图片。因此,**Delivery Hero** 的数据科学家提出了一种利用 AI 进步生成高质量产品图片的复杂方法。他们的方法包括两个阶段:食品图像生成和安全系统。
让我们首先讨论食品图像生成阶段。
**食品图像生成**
**Delivery Hero** 实现了两种方法来生成产品图像:一种涉及调用可用生成 AI 平台的 API,另一种使用图像修复方法。
**使用流行图像生成模型的食品图像生成**
有几种 AI 模型可用于生成高质量、逼真的图像,包括 DALL-E、Midjourney 和稳定扩散。为此,**Delivery Hero** 使用 DALL-E 来生成食品图像。
像 GPT-3 模型一样,DALL-E 使用 Transformer-decoder 块作为其骨干。这并不令人惊讶,因为 Transformer 架构非常通用,能够生成不同模态的数据,如文本和图像。本质上,DALL-E 被训练用于从文本描述生成图像。
由 DALL-E 从文本描述生成的示例图像
使用 DALL-E 生成图像很简单。唯一的要求是提供描述你希望它生成的图像的文本提示。**Delivery Hero** 用于生成食品图像的提示如下:
“专业照片 {dish} 和 {dish\_attributes} 放在一个漂亮的盘子上,{background} 背景”
有了这个提示,**Delivery Hero** 生成了具有特定属性和背景的菜肴的高质量图像。
**使用图像修复的食品图像生成**
**Delivery Hero** 生成食品图像的第二种方法涉及一种修复技术。图像修复指的是替换图像的特定区域的过程。
总的来说,**Delivery Hero** 实现了四个步骤,使用这种方法生成食品图像:
1. **图像选择**:从他们的数据中心选择一道菜的图像。
2. **对象检测**:使用对象检测模型检测图像中的食物对象。作为输出,获得检测到的食物的边界框。
3. **图像遮罩**:通过将像素值替换为黑色或白色,移除边界框内的区域。
4. **图像修复**:使用图像生成模型用我们选择的菜肴填充图像中被移除的区域。
使用修复技术生成图像
**Delivery Hero** 采用这种方法使用了两个模型:Grounding DINO 用于对象检测和 DALL-E 用于图像修复。
现在,让我们剖析上述图像修复方法的每个要点。我们可以跳过图像选择步骤,因为它很简单。更有趣的是使用 Grounding DINO 进行对象检测的步骤。
简单来说,Grounding DINO 是一个对象检测模型,它以一对文本和图像作为输入。它使用三种不同的输入融合方法:一个特征增强器、一个语言引导的查询选择和一个跨模态解码器,有效地结合文本和图像输入,产生一个强大的对象检测模型。
特征增强器和跨模态解码器的高级架构与 Transformer 块架构非常相似,包括注意力层和前馈神经网络。然而,这两个组件都有复杂的图像到文本和文本到图像交叉注意力层,以融合文本和图像输入,如下所示的可视化:
特征增强器和跨模态解码器的高级架构.png
你可以很容易地使用 HuggingFace 实现 Grounding DINO。如果你想跟随,本文中演示的代码可以在 这个笔记本 中找到。
假设我们想从下图中检测一个杯子蛋糕。以下代码片段可以使用 Grounding DINO 获得蛋糕的边界框。
**安装依赖**
**模型和处理器**
**加载图像**
**模型输入**
**后处理**
**输出**
[{'scores': tensor([0.8716]), 'labels': ['a cake'], 'boxes': tensor([[244.4494, 233.1335, 360.1640, 333.2773]])}]
使用 Grounding DINO 从图像中检测杯子蛋糕.png
我们可以检测到提供的图像中的蛋糕对象!
接下来,我们可以使用遮罩方法移除由 Grounding DINO 检测到的对象。应用遮罩方法后,我们应该获得一个图像输出,其检测到的边界框内外区域的像素值对比强烈。
遮罩由 Grounding DINO 检测到的内容.png
现在我们有了图像的遮罩版本,让我们实现图像修复步骤。
由于 DALL-E 不是开源模型,且使用其 API 不免费,我们将在以下示例中用一个开源图像生成模型替换这个模型。具体来说,我们将在 HuggingFace 的帮助下实现 Stable Diffusion 模型进行图像修复。
假设我们想要将图像中的杯子蛋糕替换为一杯咖啡。我们可以用以下代码实现:
**使用 Stable Diffusion 替换图像中的杯子蛋糕为一杯咖啡.png**
这就是我们需要做的,以重现 **Delivery Hero** 实现的图像修复方法!
**Delivery Hero** 实现的 AI 生成图像的质量非常好。通过这种方法,他们可以推荐一系列高质量的产品食品图像供供应商选择。
然而,在食品图像生成过程中,他们遇到了一个重要的问题:安全性。我们将在下一步讨论这个问题。
**构建安全系统**
前一节讨论的复杂图像生成方法依赖于文本提示。这意味着有时,图像生成模型可能会误解我们的意图。
例如,假设我们想要生成一张盘子上鸡的图像。没有任何安全控制,模型可能会生成如下图像:
我们想要的图像与没有任何安全控制的 AI 生成的图像.png
因此,我们需要一个组件来控制模型生成的图像质量。这就是安全系统发挥作用的地方。
**Delivery Hero** 基于四个组件实现安全系统:图像标记、图像居中、文本检测和图像清晰度。在聚会演讲中,**Delivery Hero** 团队重点介绍了两个组件:图像标记和图像居中。
**图像标记**
**Delivery Hero** 作为安全系统实施的第一个方法是标记由图像生成模型生成的图像。图像标记是指在机器学习模型的帮助下预测图像标签的过程。为此,**Delivery Hero** 使用了一个名为 Recognize-Anything Plus Model (RAM++) 的模型。
RAM++ 是一个功能强大的图像标记模型,具有出色的零样本泛化能力。由于其与大型语言模型(LLM)的集成,它能够识别 4585 个独特的标签。
在训练过程中,RAM++ 接收三种不同的输入:图像、文本和标签。文本和标签的结合丰富了可以从图像中推断出的视觉概念的范围。为了进一步提高模型的泛化能力,RAM++ 利用 ChatGPT 根据五种不同的提示为每个标签创建不同种类的描述:
1. 简洁地描述一下 {tag} 看起来像什么。
2. 你如何简洁地识别出一个 {tag}?
3. {tag} 看起来像什么,简洁地说?
4. 一个 {tag} 的识别特征是什么?
5. 请提供 {tag} 视觉特征的简洁描述。
由 GPT 3.5 Turbo 生成的标签描述扩展了每个标签的语义含义,因此提高了图像视觉概念的范围。
然后将文本和标签描述输入到文本编码器中,而图像输入到图像编码器中。这些编码器的结果然后在所谓的对齐解码器块中融合,该块由交叉注意力层和前馈层组成,以生成图像的最终标签。
要实现 RAM++ 生成图像标签,我们首先必须安装 recognize-anything 库,然后使用命令行生成图像标签。在以下示例中,我们将预测我们在前一节中使用的图像标签。
在上述示例命令中,我们使用 Swin-Transformer 模型作为图像编码器,下面是我们应该得到的输出:
由 Swin-Transformer 模型生成的标签.png
如你所见,我们为图像获得了诸如“饮料”、“布料”、“咖啡”、“咖啡杯”、“杯子”、“杯子蛋糕”、“桌子”、“餐桌”、“盘子”等标签。
在所有 4585 个标签类别中,**Delivery Hero** 的数据科学家识别了 10 个“食品”标签和 50 个“负面”标签。“负面”标签包括与动物相关的几个标签,如“虫子”、“甲虫”、“蚂蚁”、“黄蜂”等。
使用 Swin-Transformer 模型进行图像标记.png
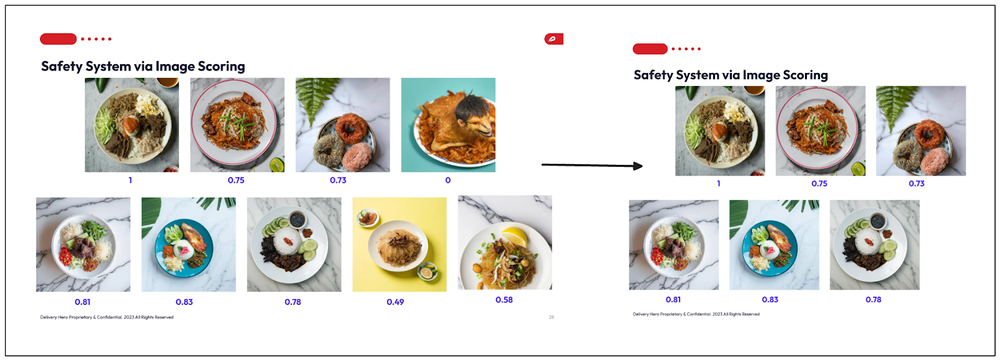
然后,他们根据 RAM++ 模型预测的标签为每个 AI 生成的食品图像分配了分数。
- 如果图像包含至少一个“食品”标签且没有“负面”标签,则分数为 1。
- 如果图像包含“负面”标签,则分数为 0。
**图像居中**
**Delivery Hero** 的数据科学家实施的另一个增强 AI 生成图像安全性的组件是图像居中。在该组件中,评估生成图像的比例。正如你可能已经知道的,图像中心的食物比边缘的食物或从图像中剪切的食物更具吸引力。
为了评估图像的比例,**Delivery Hero** 利用前一节中描述的 Grounding DINO 来检测图像中的食物对象。然后,模型产生的边界框将被评估以确定图像的质量。
评分系统如下:
- 如果没有检测到食物或盘子对象,则为 0。
- 如果边界框触及图像边缘,则为 0.5。
- 如果边界框位于图像中心,则为 1。
最后一步是将每个组件的分数与加权函数结合。最后,每个图像都有来自四个组件的加权分数。通过应用阈值值,加权分数低于该阈值的图像将被过滤掉,不推荐给供应商。
图像评分.png
**结论**
在本文中,我们讨论了 **Delivery Hero** 的两位数据科学家如何使用 AI 模型生成高质量的食品图像以改善用户体验和转化率。他们的方法包括两个阶段:食品图像生成和构建安全系统。
他们使用 OpenAI 的 DALL-E 生成图像,并在 Grounding DINO 和 DALL-E 的帮助下实现了图像修复方法。团队采用了四个组件来生成最终分数以确定生成图像的安全性:图像标记、图像居中、文本检测和图像清晰度。从这四个组件获得的分数随后与加权函数结合,为每个图像赋予一个最终分数值。通过应用阈值,最终分数低于阈值的图像将被过滤掉,不推荐给供应商。
你可以通过 这个笔记本 访问本文中演示的代码。
你可以在 YouTube 上观看 **Delivery Hero** 团队的演讲回放。

Ruben Winastwan
Freelance Technical Writer


技术干货
如何选择合适的 Embedding 模型
检索增强生成(RAG)是生成式 AI (GenAI)中的一类应用,支持使用自己的数据来增强 LLM 模型(如 ChatGPT)的知识。 RAG 通常会用到三种不同的AI模型,即 Embedding 模型、Rerankear模型以及大语言模型。本文将介绍如何根据您的数据类型以及语言或特定领域(如法律)选择合适的 Embedding 模型。
2024-08-26
技术干货
向量搜索和RAG - 平衡准确性和上下文
Zilliz的开发者倡导者Christy Bergman,拥有丰富的AI/ML经验,最近在非结构化数据聚会上讨论了这些幻觉的影响以及它们如何影响AI系统的推出。
2024-07-26
技术干货
走向生产:LLM应用评估与可观测性
随着许多机器学习团队准备将大型语言模型(LLMs)投入生产,他们面临着重大挑战,例如解决幻觉问题并确保负责任的部署。在解决这些问题之前,有效评估和识别它们至关重要。
2024-07-26